#!/usr/bin/env python3
# -*- coding: utf-8 -*-
"""
Exemple d'utilisation de la classe de wrapping Scikit-Learn pour PyTorch.
Created on Mon Oct 21 14:42:57 2019
@author: Cyrile Delestre
"""
import numpy as np
import matplotlib.pyplot as plt
from sklearn.datasets import make_moons
from sklearn.model_selection import RandomizedSearchCV, KFold
from sklearn.metrics import make_scorer, roc_auc_score
from torch import float32
from torch.nn import Module, Softmax
from torch.nn.functional import cross_entropy
from torch.optim import Adam, Adamax
from torch.optim.lr_scheduler import ReduceLROnPlateau
from torch.utils.data import Dataset, DataLoader, random_split
from dstk.pytorch.networks import MLP
from dstk.pytorch import (BaseClassifier, check_tensor, EarlyStoppingCallback,
LRSchedulerCallback)
class dataset(Dataset):
r"""
Classe mettant les datas au format adéquat PyTorch.
Attention ! La sortie est un dictionnaire et les clefs du dictionnaire
doivent correspondre aux noms des features utilisés dans le forward de la
classe PyTorch. Idem, si une fonction collate_fn est mise en sortie du
DataLeader, il faut que les noms soient cohérents avec le forward de la
classe PyTorch.
"""
def __init__(self, data, target):
self.data = data
self.target = target
def __len__(self):
return self.data.shape[0]
def __getitem__(self, idx):
if idx > self.__len__()-1:
raise IndexError()
return {'data': check_tensor(self.data[idx,:], float32),
'target': self.target[idx]}
class MonClassifieur(Module, BaseClassifier):
r"""
Ma classe MonClassifieur hérite de Module de PyTorch et de
BaseClassifier qui permet d'avoir un environnement PyTorch compatible
Scikit-Learn. Il faut que la fonction d'initialisation soit compatible
avec le standard Scikit-Learn, donc l'implémentation du réseau ne se fait
pas dans "__init__" mais dans une fonction "build" séparée. Il est
important d'ajouter dans "__init__" l'appel vers la méthode de
construction build permettant d'instancier le réseau. Attention à l'ordre,
l'héritage doit être Module puis BaseClassifier.
Notes
-----
Les fonctions obligatoires à minima :
__init__ :
fonction d'initialisation de la classe. Elle doit être au format
Scikit-Learn, c'est-à-dire que toutes les entrées qui sont
susceptibles d'être modifiées via "set_params()" doivent avoir leur
homonyme en attributs. Penser également à instancier le réseau avec
l'appel à la méthode build. Ce n'est pas obligatoire mais alors il
faudra appelé la méthode soit même pour construire le réseau. Ne pas
oublier de commencer par initialiser la classe mère Module de PyTorch
avec super().__init__().
build :
méthode d'implémentation des éléments du réseau dans PyTorch.
L'attribut "built" doit être mis à True à la fin de cette méthode. Il
y a un attribut qui doit apparaitre ici :
- optimizer : Optionel
Il s'agit de l'optimizer du modèle. Il doit être placé en
attribut et doit être initialisé dans le build si l'une de ses
caractéristiques est susceptible d'être impactée par
"set_params()" (comme le learning rate ou le type d'optimizer,
etc.). Si l'optimizer et ses paramètres sont fixes, alors il
est possible d'initialiser l'attribut "optimizer" dans la
fonction d'initialisation __init__.
forward :
méthode indispensable à la classe mère Module de PyTorch, il s'agit de
l'application forward du réseau. Il y a 2 contraintes à cette méthode :
- args
Les noms des arguments utiles pour le calcul du forward du
modèle (les entrées) doivent posséder les mêmes noms que ceux
présents dans le dictionnaire en sortie de DataLoader, donc en
sortie de générateur de données Dataset et éventuellement de
collate_fn.
- **kargs
Autres arguments éventuellement envoyés par la méthode fit ou
autre qui ne sont pas utiles au calcul du forward. A l'inverse
tout argument indispensable au forward doit être mentionné en
argument de manière explicite.
"""
def __init__(self,
dim_in,
n_layers=2,
dim_first_lay=16,
embed_topo='linear',
inter_units=10,
alpha=0.3,
dropout_prob=0,
lr=1e-3,
optim='Adam'):
super().__init__()
self.dim_in = dim_in
self.n_layers = n_layers
self.dim_first_lay = dim_first_lay
self.embed_topo = embed_topo
self.inter_units = inter_units
self.alpha = alpha
self.dropout_prob = dropout_prob
self.lr = lr
self.optim = optim
self.build()
def build(self):
self.layer = MLP(
dim_in=self.dim_in,
dim_out=2,
dim_first_lay=self.dim_first_lay,
n_layers=self.n_layers,
embed_topo=self.embed_topo,
inter_units=self.inter_units,
alpha=self.alpha,
dropout_prob=self.dropout_prob,
activation_last_layer=Softmax(dim=1),
batchnorm=False,
dropout_last_layer=False
)
if self.optim == "Adam":
self.optimizer = Adam(self.parameters(), lr=self.lr)
elif self.optim == "Adamax":
self.optimizer = Adamax(self.parameters(), lr=self.lr)
else:
raise print("Erreur optimizer inconnu.")
def forward(self, data, **kargs):
# Permet d'assurer la présence de la dimension batch.
# Dans les méthodes de recherche des hyperparamètres optimaux cette
# dimension disparait dans les phases d'inférence.
if data.dim() == 1:
data = data.unsqueeze(0)
return self.layer(data)
# Définition de l'univers des hyper-paramètres à tester
UNIV_PARAM = dict(
n_layers=[2, 3, 4, 5, 6],
dim_first_lay=[2, 4, 16, 32, 64, 128, 256],
embed_topo=["linear", "bottleneck"],
inter_units=[16, 32, 64, 128, 256],
alpha=[0.1, 0.2, 0.3, 0.4, 0.5, 0.6],
dropout_prob=[0.2, 0.5, 0.7, 0.8, 0.9],
lr=[5e-2, 1e-2, 5e-3, 1e-3],
optim=["Adam", "Adamax"]
)
#%%
if __name__=="__main__":
# Génération d'un dataset de classification binaire test
data, target = make_moons(
n_samples=2000,
shuffle=True,
noise=0.4,
random_state=None
)
# Création d'un dataset PyTorch
data_ds = dataset(data, target)
data_train, data_eval = random_split(data_ds, [1500, 500])
eval_dataset = DataLoader(data_eval, batch_size=32)
# Chargement du modèle
model_mlp = MonClassifieur(dim_in=2)
# Création du callback permettant de réaliser un scheduler sur le
# learning rate de l'optimizer. Ici on utilise une planification du
# learning rate que va décroitre si la performance ne s'améliore pas
# d'une évaluation à une autre.
scheduler_callback = LRSchedulerCallback(
lr_scheduler=ReduceLROnPlateau,
scheduler_kwargs=dict(
factor=0.8,
patience=1,
min_lr=1e-4
),
verbose=False
)
# Création du callback permettant de réaliser le Early Stopping durant
# l'apprentissage et ainsi de garder le meilleur modèle durant la
# phase d'apprentissage.
early_stop_callback = EarlyStoppingCallback(early_stopping_rounds=5)
# Initialisation et éxécution du RandomizedSearchCV de Scikit-Learn
model_search = RandomizedSearchCV(
model_mlp,
UNIV_PARAM,
n_iter=50,
scoring=make_scorer(roc_auc_score, greater_is_better=True),
n_jobs=4,
cv=KFold(5, shuffle=True),
refit=True,
verbose=1
)
model_search.fit(
X=data_train,
y=list(map(lambda x: x['target'], data_train)),
eval_dataset=eval_dataset,
loss_fn=cross_entropy,
nb_epoch=30,
dataloader_kargs=dict(batch_size=10),
target_field='target',
callbacks=[scheduler_callback, early_stop_callback]
)
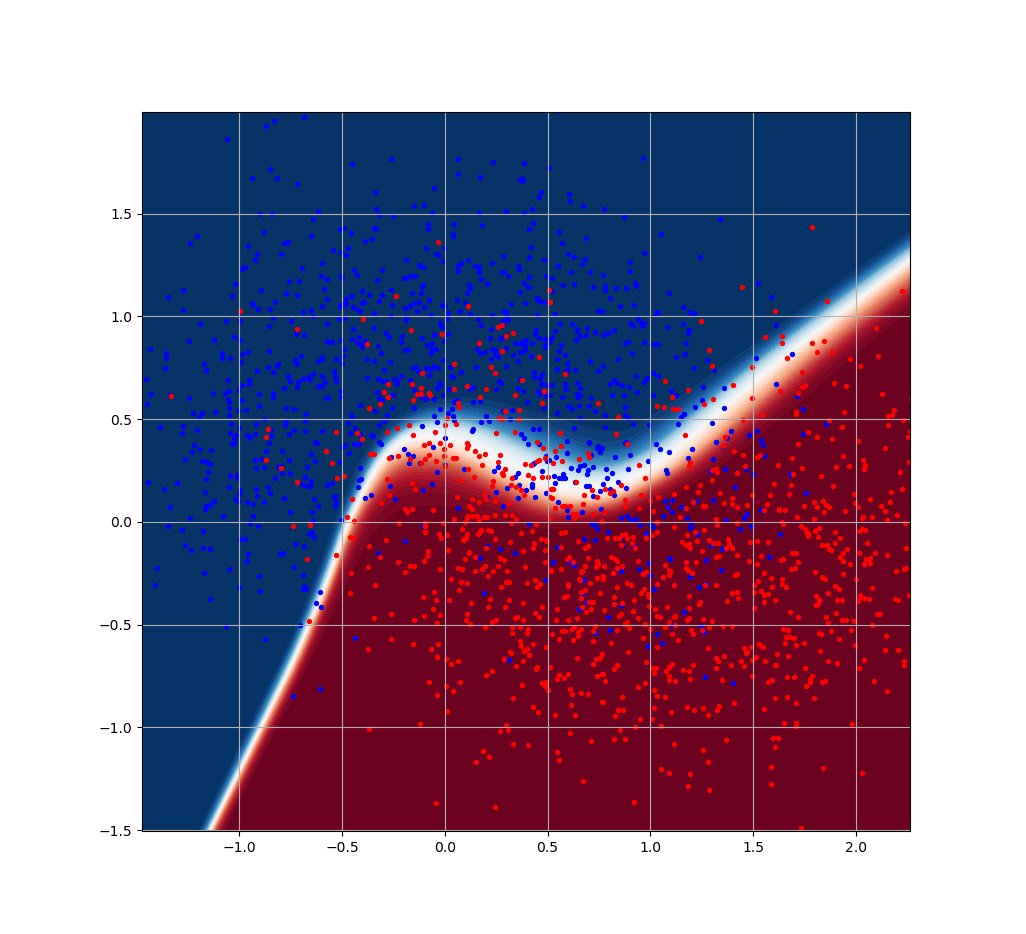
# Visualisation du résultat du modèle du best_estimator du
# RandomizedSearchCV
xx, yy = np.meshgrid(np.arange(-2, 3, 0.01), np.arange(-1.5, 2, 0.01))
c_torch = model_search.predict_proba(
np.c_[xx.ravel(), yy.ravel()].astype(np.float32)
)
plt.figure()
plt.contourf(xx, yy, c_torch[:,1].reshape(xx.shape), 50, cmap="RdBu_r")
plt.scatter(data[target==0,0], data[target==0,1], c='blue', s=8)
plt.scatter(data[target==1,0], data[target==1,1], c='red', s=8)
plt.axis('square')
plt.grid()
# Sauvegarde du modèle
model_search.best_estimator_.save_model('classif.pt');
# Reload du modèle
model = MonClassifieur.load_model('classif.pt')