visualization c’est quoi ?¶
- La librairie dstk.visualization est pour le moment essentiellement construite autour de la classe
ROCAnalyzer. Cette classe permet d’analyser et visualiser simplement les propriétés statistiques d’une classification qu’elle soit bi-classe ou multi-classe. Elle permet entre autres de : donner le seuil optimal du classifieur pour chacunes des classes ;
donner la robustesse statistique de l’estimation de la courbe ROC via
process_roc_bootstrap();donner une estimation d’une courbe ROC théorique associée au classifieur via
process_roc_theo();donner une analyse statistique détaillée du classifieur via
process_performance_matrix();etc.
Voici 2 visuels très simples à obtenir à partir de cette classe.
Premier exemple :¶
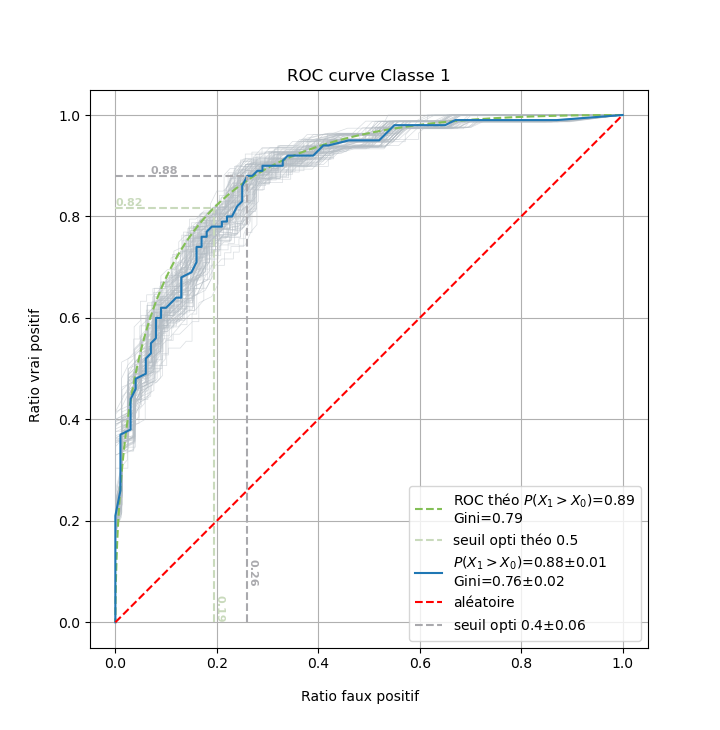
Exemple où nous réalisons un classifieur bi-classe via la modélisation random forest. Nous afficherons sur l’analyse de la courbe ROC la précision de la courbe ROC via l’approche de bootstapping, l’estimation de la courbe ROC théorique ainsi que les seuils théoriques du classifieur de tous les calculs.
from sklearn.datasets import make_moons
from sklearn.ensemble import RandomForestClassifier
from sklearn.model_selection import train_test_split
from dstk.visualization import ROCAnalyser
# Exemple de données d'une classification binaire générées
# procéduralement
data_moons, target_moons = make_moons(
n_samples = 1000,
shuffle = True,
noise = 0.5,
random_state = 42
)
(X_train_moons, X_eval_moons, y_train_moons,
y_eval_moons) = train_test_split(
data_moons,
target_moons,
train_size = 800,
random_state = 42
)
rf = RandomForestClassifier(random_state = 42)
rf.fit(X_train_moons, y_train_moons)
y_score_moons = rf.predict_proba(X_eval_moons)
ana_moons = ROCAnalyser(
y_eval_moons,
y_score_moons,
densities = ['normal', 'rayleigh']
)
ana_moons.plot_roc_bootstrap().plot_roc_theo().plot_roc()
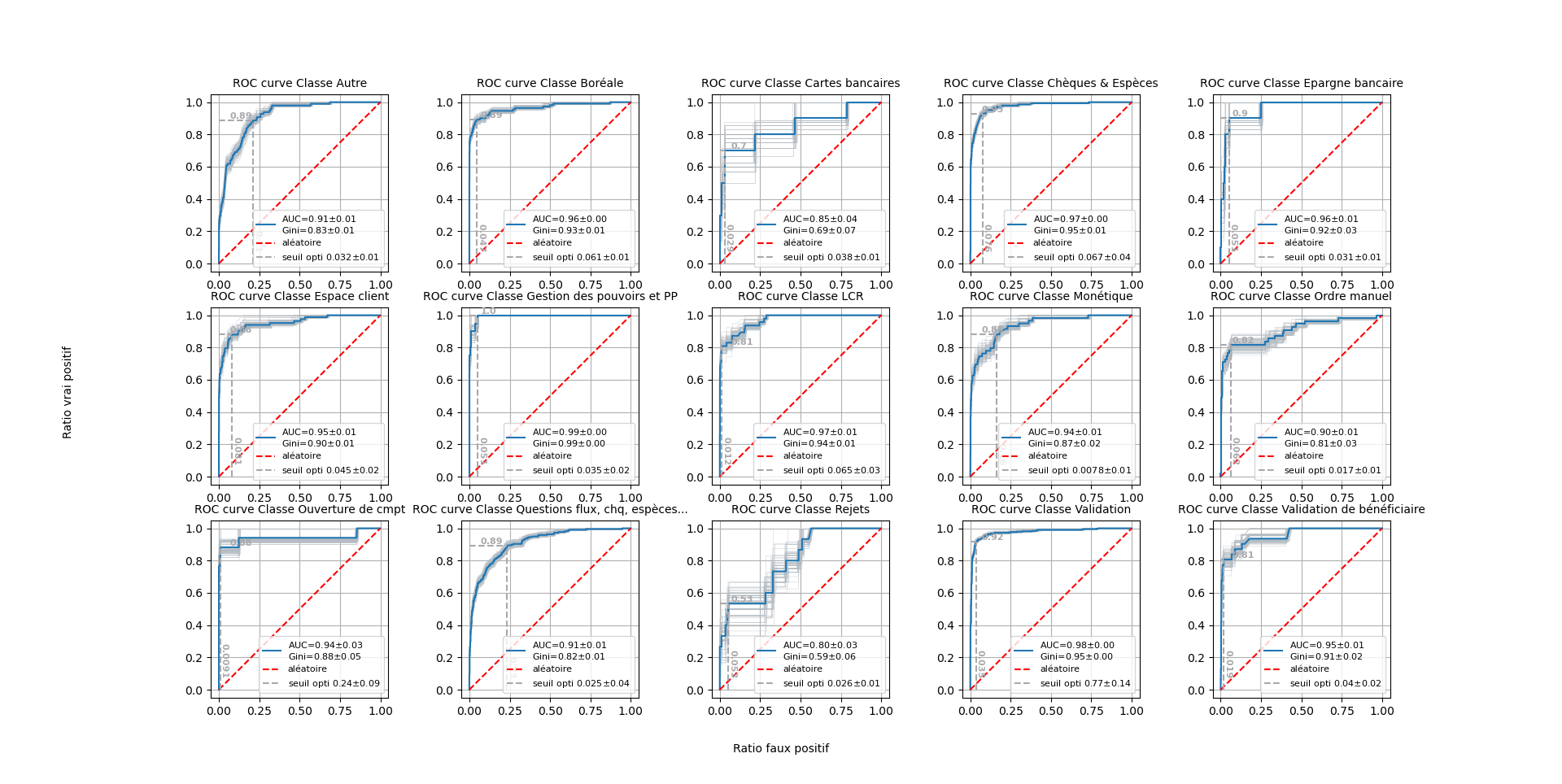
Deuxième exemple :¶
Même exercice sur un classifieur multi-classe.
from sklearn.datasets import make_multilabel_classification
from sklearn.linear_model import LogisticRegression
from dstk.visualization import ROCAnalyser
data_wine, target_wine = make_multilabel_classification(
n_samples = 1000,
n_features = 5,
n_classes = 3,
random_state = 42
)
(X_train_wine, X_eval_wine, y_train_wine,
y_eval_wine) = train_test_split(
data_wine,
np.argmax(target_wine, axis = 1),
train_size = 25,
random_state = 42
)
lr = LogisticRegression(max_iter = 1e3, random_state = 42)
lr.fit(X_train_wine, y_train_wine)
y_score_wine = lr.predict_proba(X_eval_wine)
ana_wine = ROCAnalyser(
y_eval_wine,
y_score_wine,
labels = ['Champagne', 'Bordeau', 'Beaujolais'],
densities = ['normal', 'rayleigh']
)
ana_wine.plot_roc_manager(3).plot_roc().plot_roc_theo()